The Linked Open Data Quality Assessment (LODQA) benchmark consists of 5 input data sets about Brazilian cities that have been extracted from Wikipedia editions in English, Portuguese, Spanish, German and French; as well as a gold standard data set obtained from an official source (IBGE). The input data sets are potentially incomplete, outdated or incorrect. The objective of the benchmark is to compare quality assessment and repair methods for obtaining an integrated view over those data sets that is more complete, concise and consistent than using information from each of the individual sources alone. Systems are tasked with the challenge to assess the quality of the input data sets and decide for the correct values based on that assessment. A benchmark driver is provided that compares the obtained values with the gold standard and produces evaluation scores.
The Linked Open Data cloud (LOD) is experiencing rapid growth since its conception in 2007. Hundreds of interlinked datasets compose a knowledge space which currently consists of more than 31 billion RDF triples. Given that this information comes from disparate sources, over which there is no central curation or control, quality problems often emerge. Quality problems come in different flavors, including redundant (duplicate) triples, conflicting, inaccurate, untrustworthy or outdated information, inconsistencies, invalidities and others. It has been reported that data quality problems cost businesses several billions of dollars each year. Therefore, the identification of bad quality datasets, as well as quality improvement, is an important task.
Quality is generally defined as "fitness for use". As such, it has been argued that the concept of quality is multi-dimensional, as well as context- and application-specific. Thus, in order to allow for objective evaluations of data quality, it is important to focus on specific use cases.
The Linked Open Data Quality Assessment (LODQA) benchmark focuses on a use case of obtaining an integrated view over data about cities that is more complete, concise and consistent than using information from each of the individual sources alone. This benchmark aims to reflect the real world problems that exist on the Web, and therefore focuses on existing real world Linked Data from international DBpedia editions, rather than synthetic datasets.
The LODQA benchmark allows data quality assessment and repair systems to exploit methods for assessing the plausibility of values (e.g. when some values are clearly incorrect given the expected ranges or types), outdated information (e.g. when some data sources are slower to update their values than others), and in general contrasting the perception a generally trusted source, versus some application-specific interpretation of trust (e.g. when some sources are expected to be more knowlegeable about a specific domain, while others are more trustworthy in average).
The data set for the LODQA benchmark can be downloaded from here. In this section we describe each of the underlying data sets in more details. The data is based on real world Web data extracted from the English, French, German, Spanish, and Portuguese Wikipedias through the use of the DBpedia Extraction Framework (DEF). The DEF uses community-generated mappings to associate properties from Wikipedia infoboxes to a reference ontology. The input data is described in section 2.1. Provenance is tracked by the DEF through named graphs, connecting triples to the article from which property values originated. For each source page, we also collected the date of last modification from the Wikipedia dump (described in section 2.2).
AliasesRio_de_Janeiro: this shorthand URI is used to refer to the full URI http://geo.linkeddata.es/brasil/resource/Estado%20do%20Rio%20de%20Janeiro/Rio%20de%20Janeiro.
xsd: http://www.w3.org/2001/XMLSchema# dbpont: http://dbpedia.org/ontology/ ldif: http://www4.wiwiss.fu-berlin.de/ldif/ en: http://dbpedia.org/resource/pt: http://pt.dbpedia.org/resource/fr: http://fr.dbpedia.org/resource/es: http://es.dbpedia.org/resource/de: http://de.dbpedia.org/resource/The use of five different Wikipedias in our use case aims at obtaining a wider coverage of information on Brazilian cities. Data may be absent from any particular DBpedia edition due to incomplete or missing Wikipedia infoboxes, missing mappings or irregularities in the data format that were not resolved by the DEF. Moreover, any particular Wikipedia edition may be outdated or incorrect and this could cause conflicts in the datasets (e.g., a city being associated with two different population counts).
The data set used as input for this benchmark's task comprises 3 properties (area total, population total and founding date) in a universe of 5565 cities coming from 5 sources (English, Portuguese, Spanish, German and French language editions of DBpedia).
Table 1 describes the data found across the five selected languages as well as the effect that their integration causes regarding the completeness of the dataset.
The columns labeled ``total'' show for how many Brazilian municipalities in each language there is a value for a given property. The columns labeled ``only`` shows how many of these property values are contained exclusively in the given language.

de:Rio_de_Janeiro dbpont:areaTotal "6.567E9"^^xsd:double <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . en:Rio_de_Janeiro dbpont:areaTotal "1.260029215678464E9"^^xsd:double <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . pt:Rio_de_Janeiro_%28cidade%29 dbpont:areaTotal "1.182296E12"^^xsd:double <http://pt.wikipedia.org/wiki/Rio_de_Janeiro_%28cidade%29> .
Although using different subject URIs, the triples above describe the same entity: the city of Rio de Janeiro - RJ, Brazil.
This information is encoded in DBpedia by identity links (owl:sameAs) that we also include in LODQA in the file dbpedia-sameAs.nq.gz
Example identity links
de:Rio_de_Janeiro owl:sameAs en:Rio_de_Janeiro <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . de:Rio_de_Janeiro owl:sameAs es:Rio_de_Janeiro <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . de:Rio_de_Janeiro owl:sameAs fr:Rio_de_Janeiro <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . de:Rio_de_Janeiro owl:sameAs pt:Rio_de_Janeiro_%28cidade%29 <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . en:Rio_de_Janeiro owl:sameAs de:Rio_de_Janeiro<http://en.wikipedia.org/wiki/Rio_de_Janeiro> . en:Rio_de_Janeiro owl:sameAs es:Rio_de_Janeiro <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . en:Rio_de_Janeiro owl:sameAs fr:Rio_de_Janeiro <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . en:Rio_de_Janeiro owl:sameAs pt:Rio_de_Janeiro_%28cidade%29 <http://en.wikipedia.org/wiki/Rio_de_Janeiro> .Therefore, as
de:Rio_de_Janeiro, en:Rio_de_Janeiro and pt:Rio_de_Janeiro_%28cidade%29 refer, in fact, to the same entity, in the example data above for dbpont:areaTotal there are conflicting values for the property areaTotal. Consumers of this data set will need more information to help them to choose (or transform) data in order to remove conflicts. In the next section we describe metadata that we provide with this benchmark to help with this task.
Each RDF triple in the input data set is associated to a named graph, thus composing a quadruple where the fourth element is the URI of the article from which property values originated. In the quadruple below, the areaTotal property originates from the page for Rio de Janeiro in the German Wikipedia, as indicated by the fourth element in the quadruple.
de:Rio_de_Janeiro dbpont:areaTotal "6.567E9"^^xsd:double <http://de.wikipedia.org/wiki/Rio_de_Janeiro> .
Quality-assessment-heuristics may depend on many different kinds of quality-related metadata -- see [WIQA] for an overview of possible types of metadata. Therefore, it is impossible to know in advance all types of relevant metadata that each tool may need to use. For this reason, we provide links to the source article of each triple, indicated by the 4th element of each quadruple, so that tools can access the original Wikipdia page and extract other types of metadata as needed by the tools being evaluated.
For convenience, besides the link to the source articles, we have also included in the benchmark the date of last modification from the Wikipedia dump and a sample of page view counts extracted from the Wikimedia Foundation dumps.
The provenance metadata shared in LODQA is grouped in the named graph identified by ldif:provenance.
Example metadata:
<http://de.wikipedia.org/wiki/Rio_de_Janeiro> ldif:lastUpdate "2011-07-29T20:33:39Z"^^xsd:dateTime ldif:provenance. <http://en.wikipedia.org/wiki/Rio_de_Janeiro> ldif:lastUpdate "2011-07-23T20:39:23Z"^^xsd:dateTime ldif:provenance. <http://es.wikipedia.org/wiki/Rio_de_Janeiro> ldif:lastUpdate "2007-05-12T18:12:35Z"^^xsd:dateTime ldif:provenance. <http://fr.wikipedia.org/wiki/Rio_de_Janeiro> ldif:lastUpdate "2011-07-31T04:23:56Z"^^xsd:dateTime ldif:provenance. <http://pt.wikipedia.org/wiki/Rio_de_Janeiro> ldif:lastUpdate "2011-07-15T01:50:13Z"^^xsd:dateTime ldif:provenance. <http://de.wikipedia.org/wiki/Rio_de_Janeiro> <lodqa:pageViews> 868^^xsd:integer <http://dumps.wikimedia.org/other/pagecounts-raw/2011/2011-11/> . <http://en.wikipedia.org/wiki/Rio_de_Janeiro> <lodqa:pageViews> 181259^^xsd:integer <http://dumps.wikimedia.org/other/pagecounts-raw/2011/2011-11/> . <http://es.wikipedia.org/wiki/Rio_de_Janeiro> <lodqa:pageViews> 44^^xsd:integer <http://dumps.wikimedia.org/other/pagecounts-raw/2011/2011-11/> . <http://fr.wikipedia.org/wiki/Rio_de_Janeiro> <lodqa:pageViews> 438^^xsd:integer <http://dumps.wikimedia.org/other/pagecounts-raw/2011/2011-11/> . <http://pt.wikipedia.org/wiki/Rio_de_Janeiro> <lodqa:pageViews> 1362^^xsd:integer <http://dumps.wikimedia.org/other/pagecounts-raw/2011/2011-11/> .
The Gold Standard Dataset (GS) was obtained from the Instituto Brasileiro de Geografia e Estatística (IBGE) from several spreadsheets provided in their institutional ftp server. More precisely, the name of the cities and the states they belong to, as well as their founding date, were extracted from a_legislacao_municipal_municipios_vigentes.xls file whereas the area and population total were extracted from the files in the directory containing the data from the demographic census of 2010 by states. The data was converted to RDF and shared in a SPARQL endpoint, as described in more details in [MePoBi12].
Example gold standard entry:
Rio_de_Janeiro dbpont:areaTotal "1200.279"^^xsd:double <ftp://geoftp.ibge.gov.br> . Rio_de_Janeiro dbpont:foundingDate "1565-03-01"^^xsd:date <ftp://geoftp.ibge.gov.br> . Rio_de_Janeiro dbpont:populationTotal "6320446"^^xsd:integer <ftp://geoftp.ibge.gov.br> .
In order to focus the task on quality assessment and repair, we have produced an integrated version of the raw datasets so that they use the same URIs as the gold standard. For tools that do not perform the entire data integration process, this data set can be used as the input for the quality assessment and repair process. The identity links from the raw input data sets to the gold standard are provided in the file sameAsDBpediasAndGS.nt.gz.
Example integrated data:
Rio_de_Janeiro dbpont:areaTotal "6.567E9"^^xsd:double <http://de.wikipedia.org/wiki/Rio_de_Janeiro> . Rio_de_Janeiro dbpont:areaTotal "1.260029215678464E9"^^xsd:double <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . Rio_de_Janeiro dbpont:populationTotal "6323037"^^xsd:integer <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . Rio_de_Janeiro dbpont:foundingDate "1565-03-01"^^xsd:date <http://en.wikipedia.org/wiki/Rio_de_Janeiro> . Rio_de_Janeiro dbpont:populationTotal "11875063"^^xsd:nonNegativeInteger <http://de.wikipedia.org/wiki/Rio_de_Janeiro> .
In this integrated version of the dataset, the conflicting values for the property areaTotal are directly associated to the same URI, as the owl:sameAs inference has been performed beforehand. The source of the values is retained in the named graph for each quadruple: e.g. one value comes from the German language DBpedia (as indicated by the named graph http://de.wikipedia.org/wiki/Rio_de_Janeiro, and another value comes from the English language DBpedia (http://en.wikipedia.org/wiki/Rio_de_Janeiro).
The LODQA benchmark driver can be downloaded from here. The source code is also available under Apache License V2.0.
Running:
java -jar lodqa-0.1.jar inputDataset.{nt|nq} goldStandardDataset.{nt|nq} areaTotalTreshold populationTotalTreshold
The first parameter inputDataset is the resulting file from your data quality analysis, and should contain only the correct value for each subject/property. The second parameter goldStandardDataset is the gold standard file provided in this page, containing the correct values for each subject/property. The two subsequent parameters establish thresholds for considering values correct if they "are close enough" to the values in the gold standard by a given threshold provided in areaTotalThreshold and populationTotalThreshold.
Example run:
java -jar lodqa-0.1.jar sieveOutput.nq goldStandardDataset.nq 0.005 0.2
Example benchmark results:
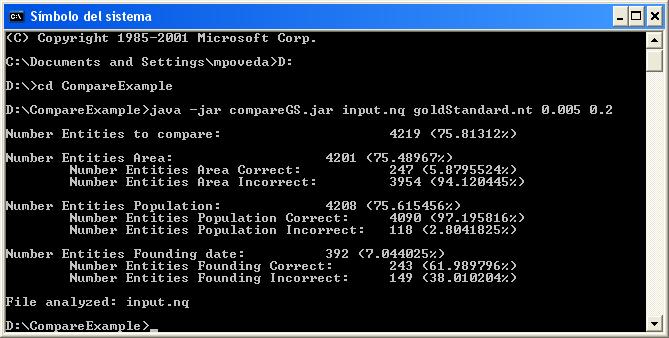
The output generated by the benchmark produces the following figures:
Number Entities to compare: #Entities #Entities*100/5565
Number Entities Area: #EntitiesArea #EntitiesArea*100/5565
Number Entities Area Correct: #AreaCorrect #AreaCorrect*100/#Area
Number Entities Area Incorrect: #AreaIncorrect #AreaIncorrect*100/#Area
Number Entities Population: #Population #Population*100/5565
Number Entities Population Correct: #PopulationCorrect #PopulationCorrect*100/#Population
Number Entities Population Incorrect: #PopulationIncorrect #PopulationIncorrect*100/#Population
Number Entities Founding date: #Founding #Founding*100/5565
Number Entities Founding Correct: #FoundingCorrect #FoundingCorrect*100/#Founding
Number Entities Founding Incorrect: #FoundingIncorrect #FoundingIncorrect*100/#Founding
Where:
All of the files for the benchmark can be downloaded from here.
We would like to thank Alexandru Todor, Mariano Rico and Julien Cojan as well as the DBpedia Internationalization Committee for their support in collecting the data for this benchmark.
This work was supported by the European Commission's Seventh Framework Programme FP7/2007-2013 (PlanetData, Grant 257641) and the Spanish mobility and internationalization program for PhD studies (Orden EDU/2719/2011. Ministerio de Educación).

This work is licensed under a Creative Commons Attribution 3.0 Unported License.